How Do Large Language Models (LLMs) Contribute to Advancing Machine Learning?

Large Language Models (LLMs) have revolutionized the landscape of machine learning, particularly in the realm of natural language processing (NLP). These sophisticated models, built on neural networks and trained on vast datasets, enable machines to understand, generate, and manipulate human language with remarkable accuracy. By leveraging techniques such as transfer learning, LLMs can adapt to various tasks from text generation and translation to sentiment analysis significantly enhancing the efficiency and effectiveness of machine learning applications.

Moreover, their ability to process and analyze massive amounts of text data has paved the way for more advanced insights and decision-making capabilities in industries ranging from healthcare to finance. As LLMs continue to evolve, they not only improve existing algorithms but also inspire the development of innovative approaches to complex challenges, pushing the boundaries of what machine learning can achieve.
This transformation is not just about improving performance; it’s also about making AI more accessible, as LLMs facilitate the creation of user-friendly interfaces that bridge the gap between technology and everyday users. Ultimately, the role of LLMs in advancing machine learning is pivotal, setting the stage for the future of intelligent systems.
What are Large Language Models (LLMs)?
Large Language Models (LLMs) are advanced artificial intelligence systems designed to understand, generate, and manipulate human language. Built on deep learning architectures, particularly transformer models, LLMs are trained on extensive datasets comprising text from books, websites, and other sources, enabling them to learn the complexities of language, context, and meaning. These models excel at various tasks, including text completion, translation, summarization, and sentiment analysis, making them versatile tools for natural language processing (NLP) applications.
LLMs operate by predicting the next word in a sequence based on the preceding context, allowing them to generate coherent and contextually appropriate responses. Notable examples include OpenAI’s GPT series and Google’s BERT, which have significantly advanced the capabilities of machine learning in understanding human language nuances.
While LLMs offer numerous benefits, such as improved efficiency in content creation and customer interactions, they also pose challenges related to bias, misinformation, and ethical considerations. As research and development continue, LLMs are set to play an increasingly pivotal role in various fields, including healthcare, education, and business, shaping the future of human-computer communication.
Evolution of Language Models
The evolution of language models has undergone significant transformations over the decades, marked by advancements in computational power, data availability, and algorithmic innovations. Initially, language models relied on simple statistical methods, such as n-grams, which assessed word sequences based on frequency. However, with the advent of neural networks, models began to incorporate deeper layers and more complex architectures. The introduction of recurrent neural networks (RNNs) and long short-term memory (LSTM) networks improved the handling of context over longer sequences.
The real breakthrough came with the development of transformer architecture in 2017, exemplified by models like BERT and GPT. Transformers leverage self-attention mechanisms, allowing for a better understanding of word relationships in context. This shift paved the way for Large Language Models (LLMs) that can process vast datasets and generate human-like text. Today, LLMs continue to evolve, incorporating more sophisticated training techniques and ethical considerations, solidifying their role in various applications from chatbots to content creation, and driving the future of natural language processing.
Defining Large Language Models (LLMs) in the Machine Learning Landscape
Large Language Models (LLMs) represent a significant advancement in the machine learning landscape, redefining how machines process and understand human language. Defined by their extensive architecture, LLMs typically consist of billions of parameters, allowing them to capture complex linguistic patterns and contextual nuances. These models are built on neural network frameworks, particularly transformer architecture, which utilizes self-attention mechanisms to analyze relationships between words in a sentence effectively. This capability enables LLMs to perform a wide range of tasks, from text generation and summarization to translation and sentiment analysis, all while generating coherent and contextually appropriate responses.
LLM development services are trained on vast and diverse datasets, enhancing their versatility and adaptability across various domains. However, their complexity also presents challenges, including ethical considerations around bias, misinformation, and resource consumption. As LLMs continue to evolve, they are becoming integral to applications such as virtual assistants, chatbots, and content generation tools, fundamentally altering the interaction between humans and technology in the digital age.
Core Technologies Behind LLMs
Large Language Models (LLMs) are built upon several core technologies and concepts in natural language processing (NLP) and machine learning. Here are the key technologies involved:
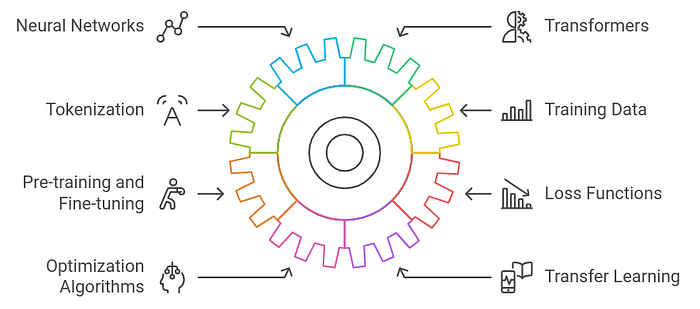
➥ Neural Networks: LLMs primarily use deep neural networks, particularly transformer architectures, to process and generate text. These networks are composed of layers of interconnected nodes that learn to recognize patterns in data.
➥ Transformers: Introduced in the paper “Attention is All You Need” by Vaswani et al. (2017), transformers are the backbone of most modern LLMs. They utilize a mechanism called self-attention, which allows the model to weigh the importance of different words in a sentence, irrespective of their position. This enables better understanding of context.
➥ Tokenization: Text input is broken down into smaller units, called tokens, which can be words or subwords. This process helps the model understand and process language more effectively. Techniques like Byte Pair Encoding (BPE) or WordPiece are commonly used for tokenization.
➥ Training Data: LLMs are trained on vast amounts of text data sourced from the internet, books, articles, and other written content. The quality and diversity of this data are crucial for the model’s performance.
Pre-training and Fine-tuning:
- Pre-training: Models are initially trained on a large corpus of text in an unsupervised manner to learn language patterns, grammar, and facts.
- Fine-tuning: After pre-training, models can be further trained on specific datasets for particular tasks, such as sentiment analysis or question-answering, using supervised learning techniques.
➥ Loss Functions: During training, LLMs use loss functions (like cross-entropy loss) to evaluate how well the model’s predictions match the actual outputs. This guides the model in adjusting its parameters to improve performance.
➥ Optimization Algorithms: Techniques like Adam, SGD (Stochastic Gradient Descent), and others are used to optimize the weights of the neural network during training, ensuring faster convergence to an optimal solution.
➥ Transfer Learning: LLMs leverage transfer learning, where knowledge gained while solving one problem is applied to a different but related problem. This is particularly effective in NLP tasks, where the model can transfer learned language representations to specific tasks with limited data.
➥ Scalability: LLMs are designed to scale effectively with increased data and model size. This includes distributed training techniques that allow models to be trained on multiple GPUs or TPUs across different machines.
➥ Ethics and Bias Mitigation: Addressing biases inherent in training data is an essential aspect of LLM development. Techniques for bias detection and mitigation are increasingly important in the responsible deployment of LLMs.
These technologies work together to enable LLMs to understand, generate, and manipulate human language with remarkable accuracy and fluency.
Functions of LLMs in Natural Language Processing
Large Language Models (LLMs) play a crucial role in various functions within Natural Language Processing (NLP). Here are some key functions of LLMs in NLP:
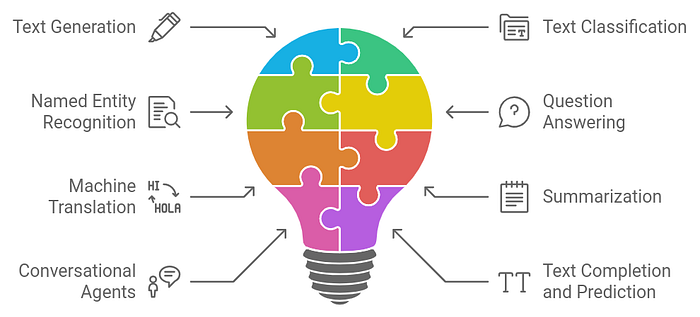
➫ Text Generation:
- Content Creation: LLMs can generate coherent and contextually relevant text for articles, blogs, and other written content based on prompts.
- Creative Writing: Assisting authors by providing suggestions for storylines, character development, or even completing sentences.
➫ Text Classification:
- Sentiment Analysis: Determining the sentiment (positive, negative, neutral) expressed in a piece of text, useful for customer feedback and reviews.
- Topic Classification: Categorizing text documents into predefined topics or themes, facilitating organization and retrieval of information.
➫ Named Entity Recognition (NER):
- Identifying and classifying entities (like names of people, organizations, locations, dates, etc.) in text, which is essential for information extraction.
➫ Question Answering:
- LLMs can comprehend and answer questions posed in natural language, drawing from extensive knowledge and context understanding.
➫ Machine Translation:
- Translating text from one language to another while maintaining the original meaning, idiomatic expressions, and cultural nuances.
➫ Summarization:
- Extractive Summarization: Selecting key sentences or phrases from a document to create a summary.
- Abstractive Summarization: Generating a concise summary that captures the essence of the content using new phrasing.
➫ Conversational Agents:
- Chatbots and Virtual Assistants: Enabling more natural and context-aware interactions in customer service and personal assistant applications.
➫ Text Completion and Prediction:
- Autocompleting sentences or suggesting the next word/phrase based on the context of the conversation or text being written.
➫ Paraphrasing:
- Rewriting sentences or passages while preserving the original meaning, useful for content rewriting, plagiarism prevention, and learning tools.
➫ Semantic Similarity:
- Measuring the similarity between texts to determine whether they convey similar meanings, which is valuable in various applications like duplicate detection.
➫ Dialogue Systems:
- Facilitating multi-turn conversations where the model maintains context over several exchanges, crucial for effective interaction in chatbots and virtual assistants.
➫ Data Annotation and Labeling:
- Assisting in automatically labeling and annotating data for various machine learning tasks, improving efficiency in dataset preparation.
➫ Language Modeling:
- Understanding and predicting language patterns, which underpins many other functions in NLP and helps improve model performance in various tasks.
➫ Contextual Understanding:
- Analyzing and interpreting context within a text, allowing for more accurate understanding and generation of nuanced content.
➫ Error Detection and Correction:
- Identifying and suggesting corrections for grammatical errors or awkward phrasing in written text.
These functions highlight the powerful capabilities of LLMs in transforming how machines understand, generate, and interact with human language, enabling advancements across various NLP applications.
Conclusion
In conclusion, Large Language Models (LLMs) are at the forefront of transforming machine learning by enhancing how machines comprehend and interact with human language. Their ability to analyze vast datasets and generate coherent, contextually relevant text has opened new avenues for applications across various sectors, including customer service, content creation, and data analysis.
As LLMs continue to evolve, they not only improve existing methodologies but also drive innovation in developing new algorithms and technologies. By enabling more sophisticated interactions and fostering greater accessibility to AI, LLMs are bridging the gap between technical complexity and user experience, allowing businesses and individuals to harness the power of artificial intelligence effectively.
Moreover, the ethical considerations surrounding the deployment of LLMs underscore the need for responsible development and usage, ensuring that advancements in machine learning are aligned with societal values. As we look to the future, LLMs will undoubtedly play a critical role in shaping the next generation of intelligent systems, making them indispensable tools for driving progress and unlocking new possibilities in an increasingly data-driven world.











Post Comment